Don’t Replicate – Federate
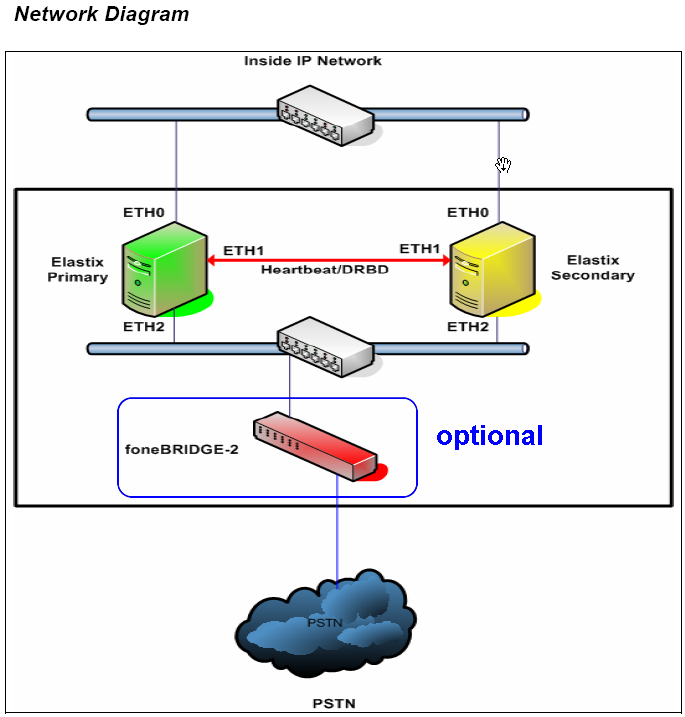
For many years, the question of high availability had always circled the same old subject of replication – how do we replicate data across nodes? how do we replicate the configuration to stay unified across nodes? Is active-active truly better than active-passive? and most importantly, what happens beyond the two node scenario?
Federating Asterisk – truth or myth?

During this years’ Asterisk Developers’ Conference, one of the subjects I’ve raised an issue for Asterisk is: “Federating Multiple Asterisk Instances”. Now, for the seasoned Asterisk user/developer, the answer would be simple – use Kamailio/OpenSIPS for that scalability, and use Asterisk as a Media Gateway or application server.
The Asterisk scaleability Unicorn

Asterisk Scaleability is somewhat of a unicorn – not because it doesn’t exist, it is a little tricky to do and get it right first time.
Astricon 2014 – Start your engines!

Ok All, this is my official Astricon Countdown – start your engines, as Eric Klein and myself will be attending Astricon this year, Vegas here we come.
Building your Asterisk based Business – Part I
Since the inception of GreenfieldTech, back in 2007, we’ve assisted over 40 different VoIP companies to bootstrap their activities and launch their products. During that period, some of these companies had become a great success and some had disappeared from the face of the planet. This series of posts will bring the story of some of them – and we’ll try to analyze what made each company into a success or a failure.
Extreme Asterisk Cloud Performance – Part I
Here’s a challenging question for the Asterisk technical savvy of you… What is the top performance you can squeeze out of an Asterisk box, running on Amazon EC2 – or to that extent, a cloud infrastructure? If you scout the Internet, you may find various answers – however, most of them aren’t backed up by real numbers or real information,made accessible in a normal readable form.
Recently, we’ve become heavily involved in a project requiring massive usage of cloud based infrastructure. I won’t go into details as to what the project is or what we are doing, however, I felt that some interesting facts about Asterisk 11.0.1 and Cloud infrastructure can be shared with the rest of you.
Business 2.0 – Taking the leap forward…
The following post doesn’t really fit in line with the normal spirit of the blog, simply because it’s not funny nor directly related to technology. It’s called Business 2.0, as it relates to the ever problematic question any business owner has: “When should I grow and how?”.
Astricon 2009 – Glendale, AZ – Part II
Ok, it’s day 1 (or actually day 2) for AstriCon 2009 – and here’s my report for the day.
Asterisk and Amazon EC2 – Amoocon Presentation
I recently gave a presentation at the Amoocon convention, held in Rostock, Germany – about Asterisk and Amazon EC2. Below is a medium quality video of that presentation: or you may download it here: Amazon EC2 and Asterisk video files
Virtualizing Asterisk – Digium Asterisk World, Feb 2008
Well, I just got back from the ITExpo show in Miami, Florida. I have to admit that I really enjoyed the venue, although I didn’t really have time to walk the floor. The main reason that I was unable to walk the floor was due to the fact that I gave a talk, as part […]