Pure-ism is financially dangerous

As the world around changes, services are rapidly changing from human rendered services, to bots and applications that run on your mobile device.
Digium D65 – More than a Home Run!

I love the feeling of unboxing a brand new IP phone, specifically, when it’s one that comes from Digium. Yes, I’m a little biased, I admit it – but I’ll do my best to refrain from dancing in the rain with this post.
Telephony Fraud – Further Analysis

Following yesterday’s post, I’ve decided to take another set of data – this time following the start of the year, with a specific data profile.
Telephony Fraud – Still going strong

Who would believe, in the age of Skype, Whatsapp and Facebook – telephony fraud, one of the most lucrative and cleanest form of theft – is still going strong. Applications of the social nature are believed to be harming the world wide carrier market – and carrier are surely complaining to regulators – and for […]
Statisics, Analytics – stop whacking off
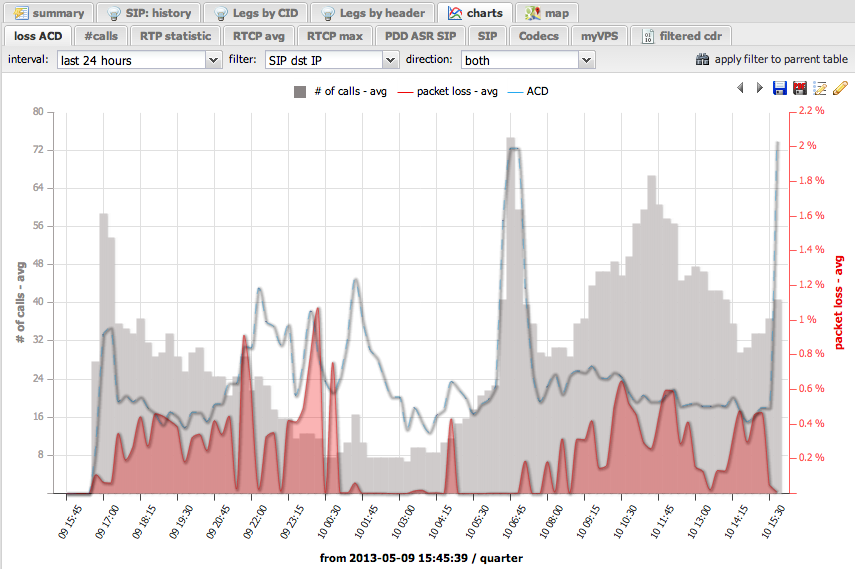
Managers! Project Managers, Sales Managers, Marketing Managers, Performance Managers – they are all obsessed! – Why are they obsessed, because we made them that way – it’s our fault! Since the invention of the electronic spreadsheet, managers relied on the same tools for making decisions – charts, tables, graphs – between us, I hate Excel or for that respect, any other “spreadsheet” product. Managers rely on charts to translate the ever complex world we live in, into calculable, simple to understand, dry and boring numbers.
Federating Asterisk – truth or myth?

During this years’ Asterisk Developers’ Conference, one of the subjects I’ve raised an issue for Asterisk is: “Federating Multiple Asterisk Instances”. Now, for the seasoned Asterisk user/developer, the answer would be simple – use Kamailio/OpenSIPS for that scalability, and use Asterisk as a Media Gateway or application server.
Astricon, Vegas and Geekness

So, Astricon 2014 is over and behind now and I’m now sitting at the Holiday Inn in Chicago. I have to admit that moving from the RedRock resort and Casino to the Holiday Inn in Chicago – talk about a mind blowing change. Just to give a general idea, the bath room in Vegas was roughly the size of the entire room here (mental note to self – next time order something better via BA miles).
The Asterisk scaleability Unicorn

Asterisk Scaleability is somewhat of a unicorn – not because it doesn’t exist, it is a little tricky to do and get it right first time.
Stanley is gone – Welcome PHPARI
In my previous post I’ve announced the bootstrapping of a new PHP project, called “Project Stanley”. Project Stanley was an attempt at creating a Asterisk ARI developer kit, based upon the PHP programming language (yes, I call it a programming language).
Asterisk ARI – What AGI/AMI should have been
Asterisk ARI – for a seasoned AGI/AMI developer like myself, ARI is a serious mind warp. Why is it a mind warp? simple, it’s all the things we wanted AGI to be, and the reliability we wanted AMI to have, minus all the work around we needed to do – in order to get similar functionality in the past.